
Lehrmaterial
1. Bruchrechnung
2. Terme und Gleichungen
2.1 Assoziativ- und Kommutativgesetz
2.2 Warum ist Minus mal Minus gleich Plus?
3. Differential- und Integralrechnung
3.2 Hauptsatz der Differential- und Integralrechnung
4. Wahrscheinlichkeitsrechnung und Statistik
4.1 Was ist Wahrscheinlichkeit?
4.2 Empirisches Gesetz der großen Zahlen
4.3 Schwaches Gesetz der großen Zahlen
4.4 Starkes Gesetz der großen Zahlen
5. Sonstiges
YouTube Kanal von Martin Wabnik
Dieser YouTube Kanal bietet über 400 hochwertige Mathematik-Videos zu verschiedenen Themen der Schulmatheamtik. Dabei geht es um ein tiefes Verständnis der Mathematik (deep learning) und nicht um die Bereitstellung sinnentleerter Lösungsrezepte. Hinter jedem Video steckt ein didaktisches Konzept, welches entschieden sprachlich und visuell umgesetzt wird. Jeder Mensch, der Mathematik wirklich verstehen möchte, wird hier das finden, wonach er lange gesucht hat.
Bruchrechnung
Die Bruchstreifen befinden sich im Google-Drive-Ordner Die besten Erklärungen der Welt und können kostenfrei heruntergeladen werden.
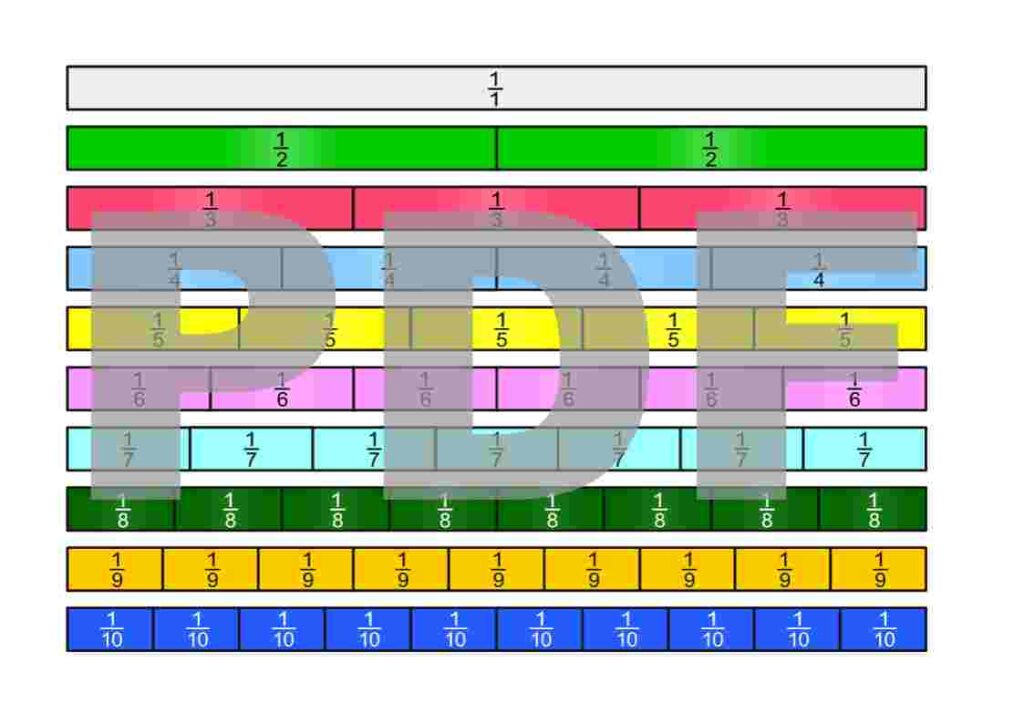
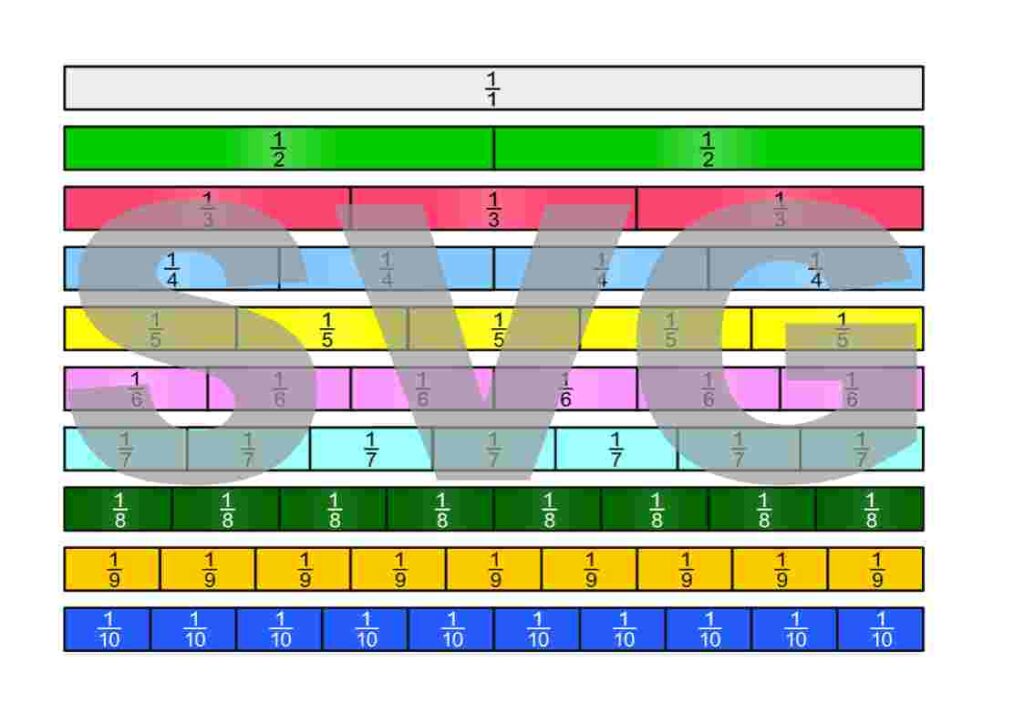
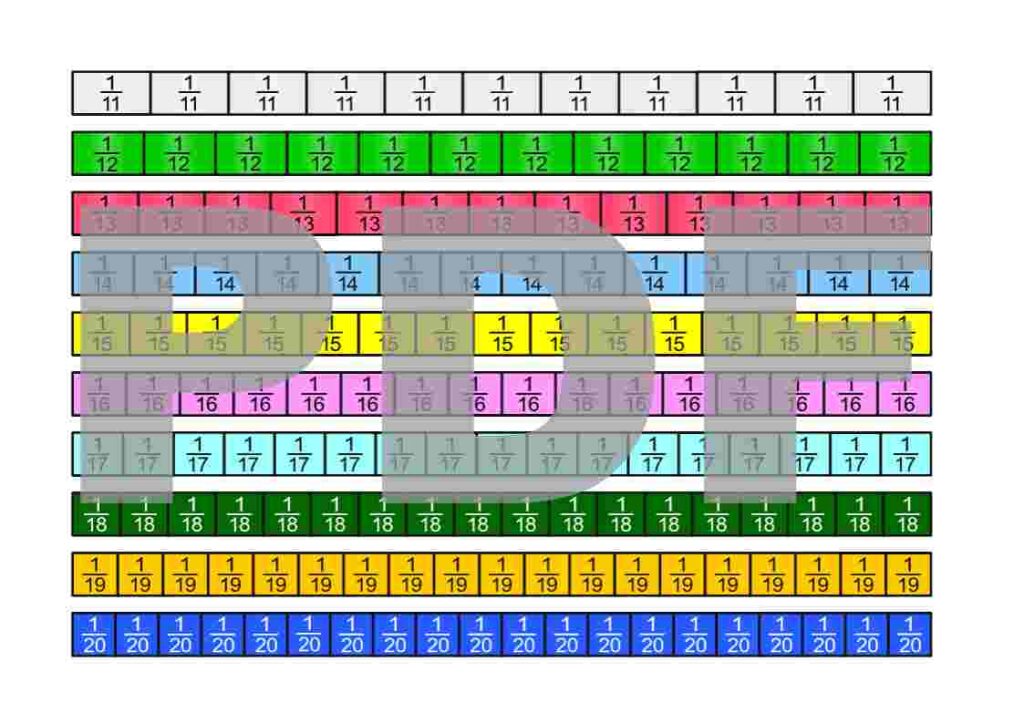
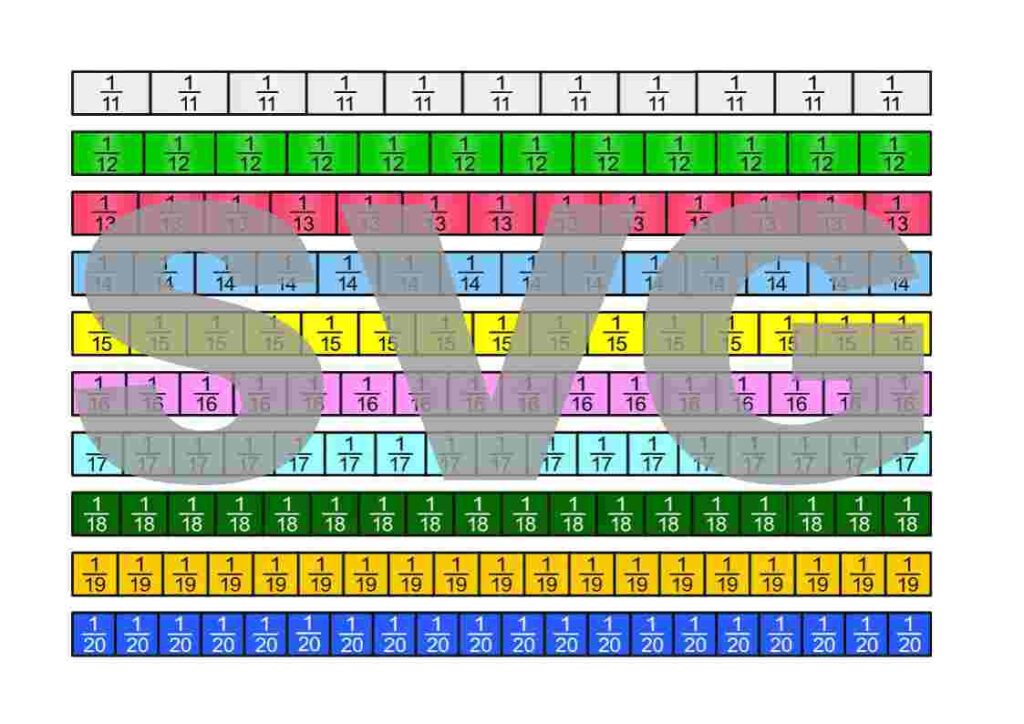
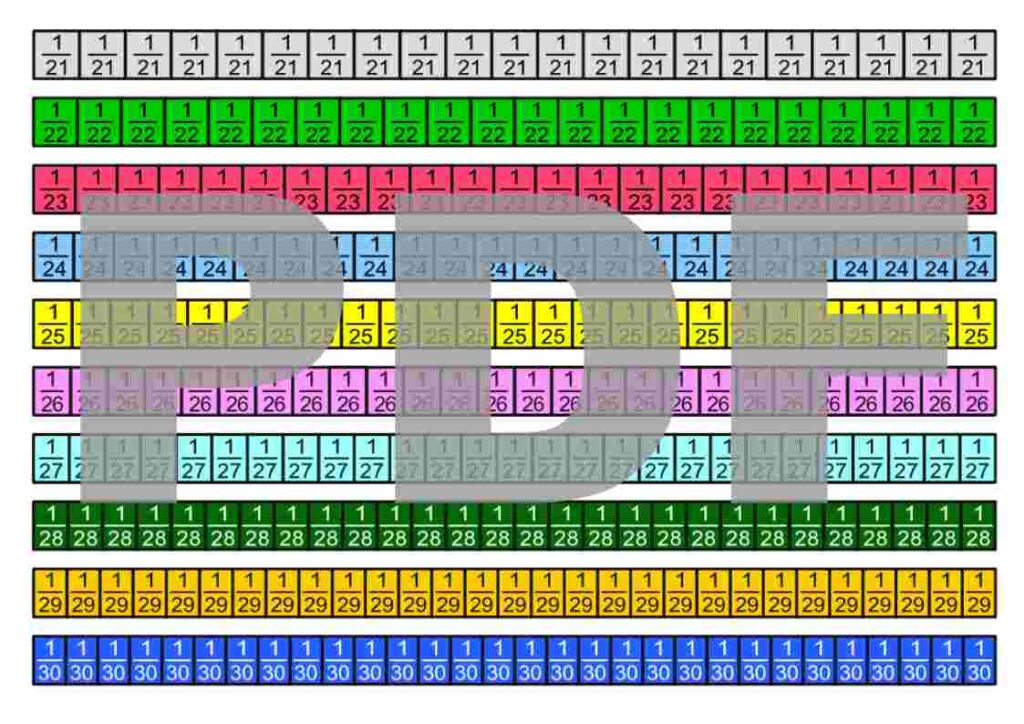
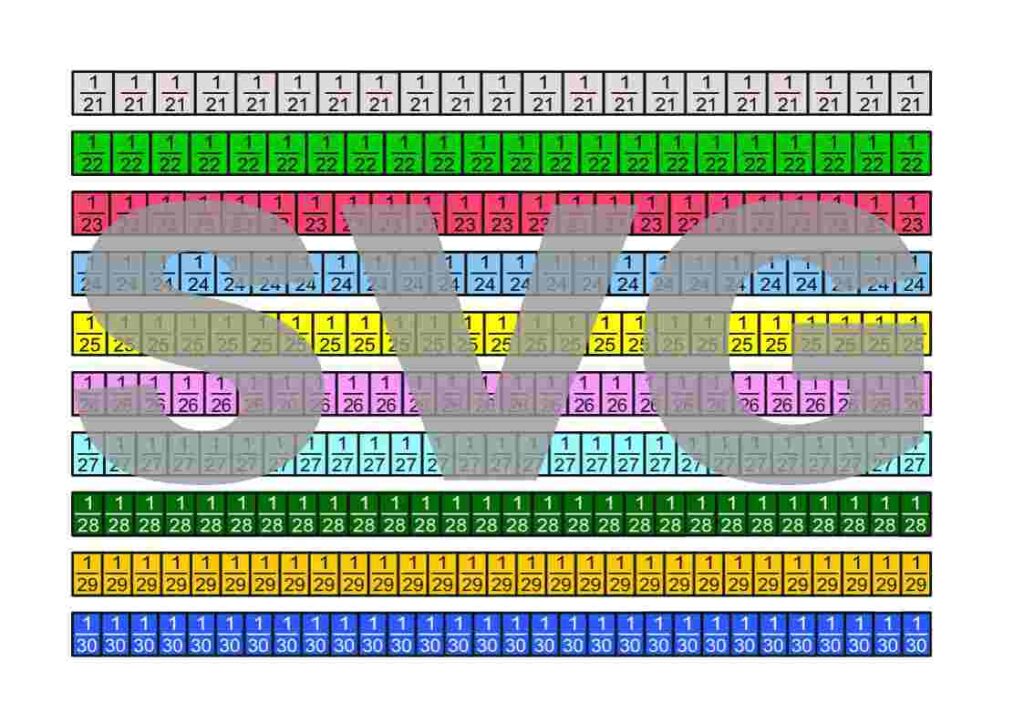
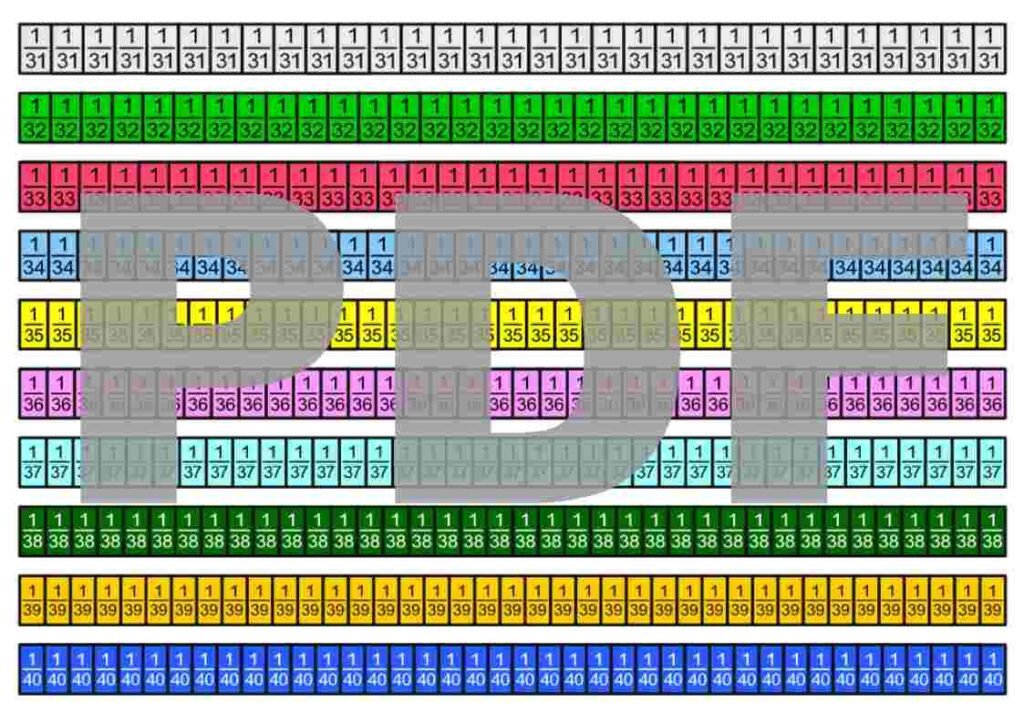
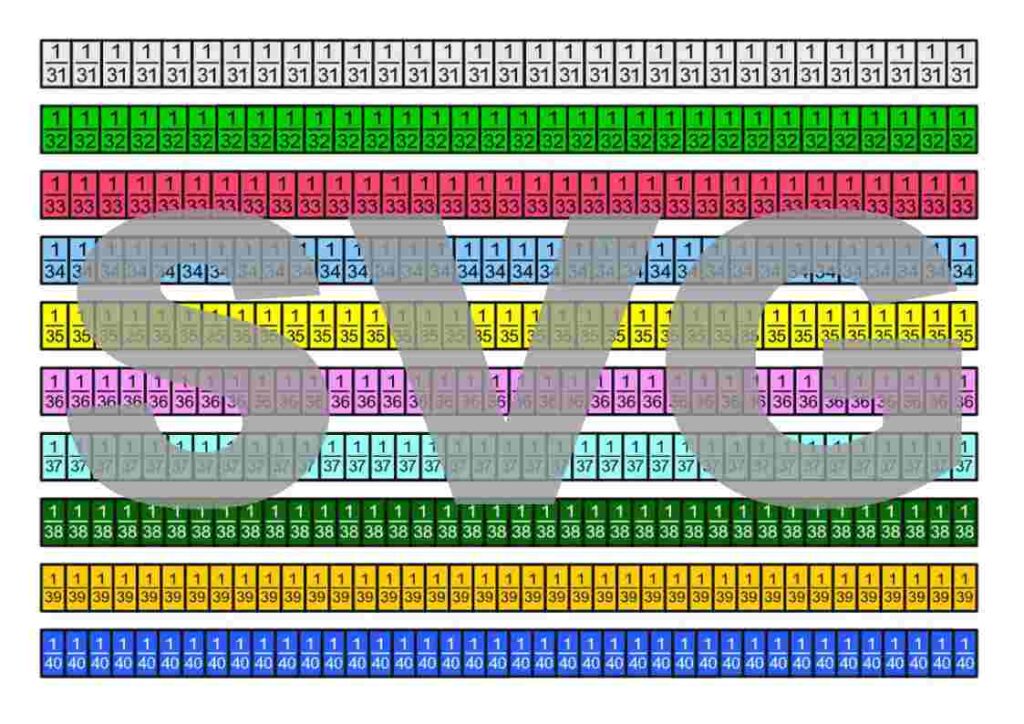
Lizenzhinweis: Ich stelle diese Materialien bewusst unter die freieste Lizenz, die es gibt: Creative Commons CC0 1.0 (Public Domain Dedication). Das bedeutet: Sie dürfen die Bruchstreifen ausdrucken, verändern, in Unterrichtsmaterialien einbauen, auf YouTube oder in Büchern verwenden, auch kommerziell. Eine Namensnennung ist nicht erforderlich.
Brüche

Es gibt viele Möglichkeiten zu definieren, was Brüche sind. Um mit Brüchen arbeiten zu können, müssen wir uns einfach für eine Definition entscheiden und aus dieser dann alle Eigenschaften von Brüchen ableiten. Wir entscheiden uns hier dafür, Brüche als Teile einer Einheit auf dem Zahlenstrahl zu sehen. Im folgenden PDF werden auch die ersten Sprechweisen gezeigt.

Brüche können in vielen verschiedenen Zusammenhängen auftauchen. Im folgenden PDF sind einige davon dargestellt.
Brüche erweitern

Wenn wir die Teile eines Bruchs in weitere Teile unterteilen, entsteht in Bruch gleicher Größe. Diesen Vorgang nennen wir „erweitern“. Wie wir uns das vorstellen können, steht im folgenden PDF.
Weitere Fragen
Wenn wir zwei Brüche erweitern, suchen wir ein gemeinsames Vielfaches der beiden Nenner. Sind die Nenner teilerfremd, ist das kleinste gemeinsame Vielfache das Produkt der Nenner.
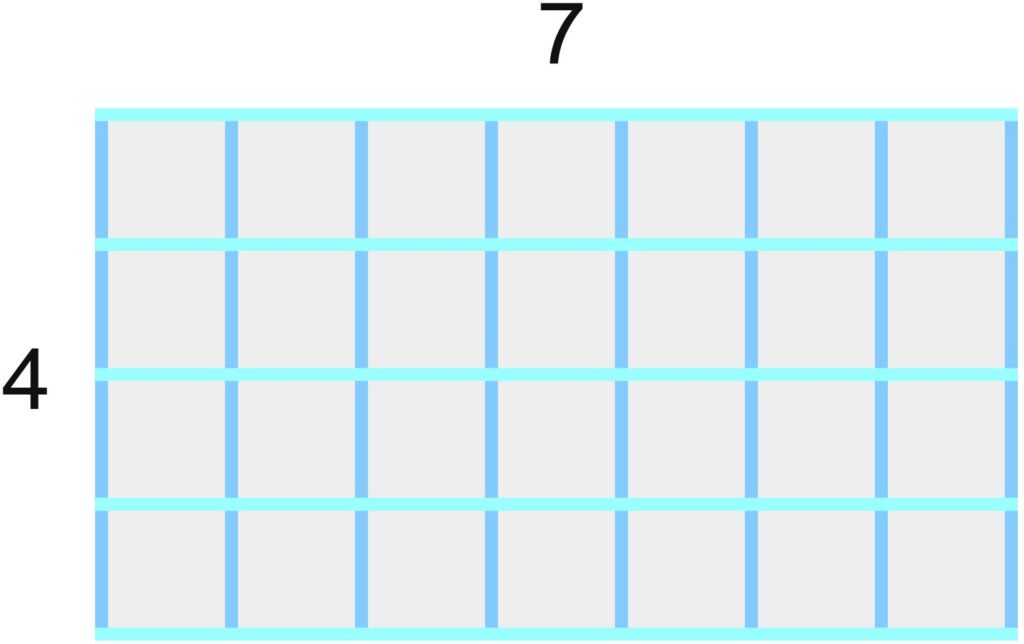
Gemeinsame Vielfache kann man sich auch mit Papierstreifen vorstellen. Haben wir mehrere Papierstreifen der Länge \(4\) und mehrere Papierstreifen der Länge \(7\), und legen wir die Vierer-Streifen sowie die Siebener-Streifen nebeneinander, wird die Gesamtlänge der Streifen irgendwann gleich sein: \(7\) Vierer-Streifen sind genauso lang wie \(4\) Siebener-Streifen.
Das funktioniert auch mit Papierstreifen, die bestimmte andere Längen haben.
Frage: Welche Längen müssen Papierstreifen haben, damit sie ein gemeinsames Vielfaches haben?
Teilantwort: Solange die Längen der Papierstreifen ganzzahlige Vielfache einer (beliebigen) Einheit sind, haben sie auch gemeinsame Vielfache.
Frage: Aber funktioniert das auch mit nicht-ganzzahligen Vielfachen? Ist z. B. die Länge eines Papierstreifens gleich \(\frac{2}{3}\) der Länge eines bestimmten Einheits-Streifens und ist die Länge des anderen Papierstreifens gleich \(\frac{3}{4}\) der Länge dieses Einheits-Streifens, haben dann diese Papierstreifen gemeinsame Vielfache? Wie sieht es aus, wenn die Längen gleich \(\frac{37}{39}\) und \(\frac{38}{39}\) einer Einheitslänge sind. Oder wie steht es mit \(\frac{41}{43}\) und \(\frac{43}{41}\)? Kann aus der Differenz der Längen der beiden Papierstreifen die Anzahlen der Streifen bestimmen, die man nebeneinanderlegen muss, damit gleiche Längen herauskommen?
Ausblick: Haben die Papierstreifen Längen, die irrationale Vielfache einer Einheitslänge sind, haben sie kein gemeinsames Vielfaches. Allerdings gibt es keinen realen Papierstreifen, dessen Länge exakt ein irrationales Vielfaches einer Einheitslänge ist.
Eine ähnliche Problematik ergibt sich aus der im PDF erwähnten Einteilung eines Fotos in Rechtecke oder Quadrate. Sicher können rechteckige Fotos, deren Seitenlängen ganzzahlige Vielfache einer (beliebigen) Einheit sind, vollständig in Quadrate unterteilt werden.
Frage: Können die Flächen von Rechtecken, deren Seitenlängen beliebig sind, vollständig in Quadrate unterteilt werden?
Frage: Können die Flächen von Rechtecken, deren Seitenlängen beliebig sind, vollständig in kleinere Rechtecke unterteilt werden? Wird das Problem einfacher, wenn die kleineren Rechtecke die gleichen Seitenverhältnisse haben wie das zu unterteilende Rechteck? Was passiert bei Rechtecken mit anderen Seitenverhältnissen`?
Frage: Können die Flächen von Rechtecken, deren Seitenlängen beliebig sind, vollständig in Quadrate unterteilt werden, wenn die Quadrate nicht alle gleich groß sein müssen?
Ausblick: Diese Fragen können auf das Thema der Parkettierungen führen. In diesem Bereich der Mathematik gibt es noch einige bisher ungelöste Probleme.
Brüche kürzen

Haben der Zähler und der Nenner eines Bruchs einen gemeinsamen Teiler, können wir den Zähler und den Nenner ohne Rest durch diesen Teiler teilen, wodurch ein Bruch gleicher Größe entsteht. Dieser Bruch besteht dann zwar aus weniger, dafür aber größeren Teilen. Im folgenden PDF schauen wir uns die Lage anhand der Bruchstreifen an.
Hauptnenner

Um zwei Brüche zu addieren, zu subtrahiern oder vergleichen zu können, erweitern wir sie so, dass sie gleiche Nenner haben. Das geht z. B. dadurch, dass wir einen Bruch mit dem Nenner des jeweils anderen Bruchs erweitern. Das kann aber zu unnötig großen Nennern führen. Deshalb erweitern wir die Brüche normalerweise nur auf den Hauptnenner. Der Hauptnenner ist das kleinste gemeinsame Vielfache beider Nenner. Im folgenden PDF wird beschrieben und an Beispielen gezeigt, wie das gemacht wird.
Brüche verlgeichen

Wir Menschen können auf Anhieb erkennen, welche von zwei gegebenen natürlichen Zahlen die größere ist. Für Brüche, die unterschiedliche Nenner haben, gilt das aber nicht unbedingt. Wenn wir aber Brüche auf gleiche Nenner erweitern, ist das kein Problem mehr.
Brüche addieren

Die Addition von Brüchen klingt zunächst ganz einfach: Brüche gleichnamig machen und dann die Zähler addieren. Tatsächlich stecken aber ein paar Schritte mehr dahinter: Brüche auf Kürzbarkeit prüfen und gegebenenfalls kürzen, den Hauptnenner bestimmen und beide Brüche auf den Hauptnenner erweitern, anschließend wieder prüfen, ob die Brüche kürzbar sind und gegebenenfalls kürzen. Im folgenden PDF werden alle diese Schritte mit den Bruchstreifen nachvollzogen – und zwar nicht nur an den einfachsten Brüchen, sondern auch an solchen, die einem gemeinen Schüler auf natürliche Weise begegnen können. Die Bruchstreifen dienen hier als Standardmodell. Wir argumentieren: Wenn die Addition von Brüchen mit den Bruchstreifen funktioniert, wollen wir davon ausgehen, dass diese Methode sinnvoll ist und auf alle Brüche angewandt werden kann.
Weitere Fragen
1) Auch wenn man gekürzte Brüche addiert, kann es vorkommen, dass der Ergebnisbruch gekürzt werden kann. Für welche Brüche gilt das? Unter welchen Bedingungen gilt das?
Anmerkung: Meiner Meinung nach müsste es ein elementares Verfahren geben, welches diese Frage beantwortet. Mir ist aber keines bekannt. Weder das Internet noch die KI konnten mir dazu Auskunft geben und meine Ansätze wurden schnell so kompliziert, dass ich dachte, falsch zu liegen.
2) Die Bruchstreifen dienen hier als Standardmodell der Bruchaddition. An ihnen können wir verstehen, wie die Addition von Brüchen anschaulich funktioniert. Wir können argumentieren: Die Addition von Brüchen können wir auch auf andere Objekte anwenden, solange sie zu den Bruchsteifen hinreichend ähnlich sind. Was kann das bedeuten? Können wir die Addition von Brüchen auch auf Objekte anwenden, die ganz anders sind als die Bruchstreifen?
Brüche werden oft als Kreissegmente dargestellt. Funktioniert die Addition von Brüchen auch mit Kreissegmenten, weil die Kreissegmente den Bruchstreifen hinreichend ähnlich sind? Oder ist es umgekehrt? Oder ganz anders?
Die Addition von Brüchen kann man auch auf Frequenzen anwenden. Sind Frequenzen ganz anders als Bruchstreifen?
3) Wenn wir Brüche als Verhältnisangaben verstehen, ergibt es dann einen Sinn, diese zu addieren? Da die Addition von Brüchen (mindestens) zwei Brüchen eine dritten – den Ergebnisbruch – zuordnet, ergibt sich die Frage: Gibt es eine andere Rechnung, die zwei Verhältnisangaben – also zwei Brüchen – eine dritte Verhältnisangabe sinnvoll zuordnet? Und was passiert, wenn wir Brüche als Anteile sehen, oder als Ergebnisse von Divisionen, oder als Rechenanweisungen?
4) Wenn ein Ganzes gleich 300 € ist, dann ist \(\frac{1}{2}\) gleich 150 €, \(\frac{1}{3}\) ist gleich 100 € und \(\frac{1}{2} + \frac{1}{3}\) ist gleich 250 €. Statt die Brüche zu addieren, könnten wir hier also auch ganze €-Beträge addieren. Kann man ein Ganzes immer so wählen, dass man statt mit Brüchen auch mit ganzen Zahlen rechnen kann? Und wenn ja: Würde das irgendetwas vereinfachen?
Anmerkung: Es gibt in der Mathematik ein ähnliches Konzept, nämlich die Prozentrechnung. Dabei wird das Ganze immer in \(100\) Teile eingeteilt. \(\frac{1}{2}\) besteht dann aus 50 dieser Teile, \(\frac{3}{4}\) besteht aus \(75\) dieser Teile und \(\frac{1}{3}\) ist ungefähr gleich 33 dieser Teile.
5) Gehen wir mal davon aus, dass jeder Bruch ein Ganzes braucht, um existieren zu können. Z. B. braucht der Bruch \(\frac{1}{2}\) ein Ganzes, um die Hälfte dieses Ganzen bezeichnen zu können. Können wir auch zwei Brüche addieren, wenn sich diese Brüche auf unterschiedliche Ganze beziehen?
Gehen wir davon aus, dass sich zwei Brüche nicht auf gleiche Ganze, sondern auf dasselbe Ganze beziehen soll, dann können wir z. B. die Brüche \(\frac{4}{5}\) und \(\frac{3}{4}\) nicht addieren, weil z. B. \(\frac{4}{5}\) vom Ganzen nur noch \(\frac{1}{5}\) übrig lässt und wir den Bruch \(\frac{3}{4}\) gar nicht mehr bilden können. Welche Brüche können wir dann unter diesen Umständen überhaupt bilden, um sie zu addieren?
Können wir auch Brüche addieren, wenn sie sich nicht auf ein Ganzes beziehen, also einfach abstrakte Brüche sind? Ergibt dann die Addition einen Sinn?
Außerdem können wir uns überlegen, was ein Ganzes überhaupt sein kann. Wenn wir \(\frac{1}{2}\) kg Teig und \(\frac{1}{3}\) kg Teig in eine Schüssel geben: Ist dann die Teigmenge in der Schüssel ein Ganzes? Und wenn ja: Hätten wir immer noch ein Ganzes in der Schüssel, wenn wir zu dem halben Kilogramm Teig noch \(\frac{1}{3}\) kg Schrauben hinzufügen?
Brüche subtrahieren

So ähnlich, wie wir Brüche addieren, können wir auch Brüche subtrahieren. Wenn wir uns diese Rechnung mit den Bruchstreifen vorstellen möchten, müssen wir aber beim Denken die Richtung wechseln und können die Bruchstreifen nicht einfach wie beim Addieren nebeneinander legen. Im folgenden PDF sind einige Beispiel ausführlich vorgerechnet.
Brüche multiplizieren

Wenn wir Brüche multiplizieren, rechnen wir Zähler mal Zähler und Nenner mal Nenner. Aber warum eigentlich? Im folgenden PDF wird gezeigt, wie wir das verstehen können. Außerdem wird an den Bruchstreifen gezeigt, warum wir „über Kreuz“ kürzen können und warum wir die Zähler sowie die Nenner vertauschen können, wenn wir Brüche multiplizieren.
Brüche dividieren
Kehrwertregel – anschauliche Begründung der Kehrwertregel – Video
Die Kehrwertregel lautet: Man teilt durch einen Bruch, indem man mit dem Kehrwert multipliziert. Eine solche Regel lässt man in der Mathematik nicht einfach so stehen, sondern sie wird begründet. Eine rein anschauliche Begründung wird in diesem Video vorgestellt.
Brüche dividieren – Begründung der Kehrwertregel – Messen

Wir teilen durch einen Bruch, indem wir mit dem Kehrwert multiplizieren. Das besagt die Kehrwertregel.
Aber warum gilt die Kehrwertregel? Um das zu klären, fragen wir uns, was das Teilen von Zahlen eigentlich bedeutet. Dafür gibt es mehrere Möglichkeiten:
Oftmals wird das Teilen von Zahlen als „Messen“ verstanden. Wenn wir \(12\) durch \(3\) teilen, können wir uns fragen: Wie oft passt \(3\) auf \(12\)? Die Antwort ist \(4\), weil \(3\) viermal auf \(12\) passt. Wenn wir die Länge einer Strecke messen, gehen wir so ähnlich vor: Wir nehmen einen Maßstab, der z. B. \(1\) Meter lang ist, und fragen uns, wie oft dieser Maßstab auf eine bestimmte Strecke passt. Wenn der Maßstab genau viermal auf diese Strecke passt, ist die Strecke \(4\) Meter lang.
Wenn wir das Teilen von Brüchen als „Messen“ verstehen wollen, können wir uns die Brüche mit den Bruchstreifen vorstellen. Im PDF wird gezeigt, wie man Brüche anschaulich dividieren kann und wie die Kehrwertregel begründet werden kann.
Didaktische Anmerkung: Im PDF wird die anschauliche Begründung mit Bruchstreifen gezeigt, an der die Gültigkeit der Kehrwertregel direkt abgelesen werden kann. Zudem wird der „schwierigste“ Fall gezeigt: beide Brüche haben unterschiedliche Zähler und Nenner, die Nenner sind nicht gleich 1 und der zweite Bruch ist größer als der erste. Es gibt zwar ähnliche, anschauliche Begründungen, aber hier ist die einzige Erklärung zu sehen, die den kompliziertesten Fall behandeln kann und die ohne Analogieschlüsse auskommt.
Brüche dividieren – Begründung der Kehrwertregel – Verteilen

Wir können das Teilen von Zahlen auch als „Verteilen“ verstehen. Wenn wir \(15\) Äpfel auf \(3\) Körbe verteilen, sind in jedem Korb \(5\) Äpfel. Deshalb ist \(15 : 3 = 5\).
Aber wie verteilt man z. B. \(\frac{4}{5}\) auf \( \frac{2}{3} \) ? Wie kann das überhaupt aussehen? Im PDF wird gezeigt, wie durch geschicktes Einteilen von Flächen die Begründung der Kehrwertregel direkt anschaulich abgelesen werden kann. In dieser kurzen Darstellung wird der „schwierigste“ Fall gezeigt: Weder Zähler noch Nenner passen zusammen, alle sind ungleich \(1\) und der Bruch, auf den verteilt wird, ist kleiner als \(1\).
Didaktische Anmerkung: Im PDF wird die einzige heute existierende anschauliche Begründung der Kehrwertregel gezeigt, die mit der Idee des Verteilens arbeitet. Auch bei dieser Begründung lässt sich die Gültigkeit der Kehrwertregel direkt ablesen. Es gibt zwar grundsätzliche Bebründungen wie z. B. das Verteilen einer Wassermenge auf Behälter mit unterschiedlich großen Grundflächen, wobei sich beim Umfüllen der Wasserstand entsprechend ändert, aber nur eine Begründung, an der man die Zahlen, mit denen multipliziert wird, direkt ablesen kann.
Terme und Gleichungen
Assoziativ- und Komutativgesetz
Die ersten beiden Formeln, die man normalerweise im Mathematikunterricht behandelt, sind diese:
1) \(a+b=b+a\) und
2) \(a+(b+c)=(a+b)+c\) Die erste Formel heißt „Kommutativgesetz der Addition“ und die zweite Formel heißt „Assoziativgesetz der Addition“. Mit diesen Formeln wird etwas beschrieben, was wir ohnehin schon aus unserem Alltag kennen: Egal, in welcher Reihenfolge wir etwas addieren, es kommt immer das gleiche Ergebnis heraus. Im Video sehen wir uns an, wie wir diese Formeln anwenden können.
Weitere Fragen
Frage 1a) Warum können wir sicher sein, dass das Assoziativgesetz und auch das Kommutativgesetz für alle Zahlen gilt? Immerhin gibt es unendlich viele Zahlen und man kann deshalb die Gültigkeit der Gesetze nicht an allen Zahlen getestet haben.
Mögliche Antwort: Wenn wir schriftlich addieren, fangen wir mit der Addition der Ziffern auf der Einerstelle an. Wenn die Summe größer als \(9\) ist, machen wir einen entsprechenden Übertrag zur Zehner-Stelle. Dann addieren wir alle Ziffern auf der Zehnerstelle, machen vielleicht noch einen Übertrag usw. Das bedeutet: „Eigentlich“ addieren wir immer nur einzelne Ziffern. Also könnten wir argumentieren: Wenn das Assoziativgesetz und das Kommutativgesetz für alle einstelligen Zahlen gilt, muss es auch für alle anderen Zahlen gelten. Wir müssten also nur noch – vielleicht durch nachrechnen – sicherstellen, dass die Gesetze für einstellige Zahlen gelten.
Frage 1b) Gilt auch das Gesetz: \(a-b=-b+a\) ? Warum?
Frage 1c) Gilt auch das Gesetz \(a-b=b-a) ? Warum?
Frage 1d) Gilt das Kommutativgesetz der Addition auf für periodische Dezimalzahlen? Warum?
Frage 2: Warum können wir sicher sein, dass das Assoziativgesetz und auch das Kommutativgesetz für alle Dinge richtig ist? Oder kann man diese Gesetze gar nicht auf alle Dinge anwenden?
Mögliche Antwort: Im Video wird nahegelegt, dass die Gesetze für Tomaten gelten, denn wie man sehen kann, bedeuten die Gesetze „eigentlich“ nur ein Umgruppieren von Tomaten. Und weil wir in einer Welt leben, in der durch das Umgruppieren Tomaten weder Tomaten verloren gehen noch neue entstehen, gelten die Gesetze wohl für alle Tomaten.
Aber was ist dann mit allen anderen Objekten? Man könnte argumentieren, die Gesetze gelten auch für alle Objekte, die so ähnlich sind wie Tomaten. Dann müsste man sich nur noch überlegen, was „ähnlich“ bedeuten soll.
Frage 3: Im Video wurde gesagt, dass das Kommutativgesetz für Schritte gilt. Es wurde aber nicht gesagt, dass das Assoziativgesetz für Schritte gilt. Also: Gilt das Gesetz auch für Schritte? Wie kann man sich z. B. \(3+(2+4)\) im Zusammenhang mit Schritten vorstellen? Kann man denn erst \(2+4\) Schritte gehen und erst danach die ersten \(3\) Schritte gehen? Nach dem Sprichwort „Man kann nicht den zweiten Schritt vor dem ersten gehen“ geht das nicht. Man könnte aber auch Papierstreifen herstellen, die einer Schrittlänge entsprechen, dann erst \(2+4\) „Schrittlängen“ auf den Boden legen und anschließend \(3\) Papierstreifen davor legen. Aber ist das dann noch das, was mit „gehen“ gemeint ist?
Frage 4: Für welche Dinge gelten die Gesetze nicht?
Mögliche Antwort: Die Gesetze gelten nicht für solche Dinge, die man nicht addieren kann, wie z. B. Gerechtigkeit oder Liebe. Aber gibt es Dinge, die man addieren kann, für die aber diese Gesetze nicht gelten?
Frage 5: Im Video wird gezeigt, wie man Zahlen für Variablen einsetzen kann. Kann man denn für die Variablen auch noch etwas anderes einsetzen? Kann man z. B. für \(a\) auch \(7+9\) einsetzen? Oder \(f+g\) ? Gelten die Gesetze dann immer noch?
Mögliche Antwort: Grundsätzlich kann man in mathematischen Formeln (zumindest in denen, die im Schulstoff vorkommen) die Variablen nicht nur durch Zahlen, sondern auch durch Terme ersetzen. Die Argumentation dabei ist: Laut Definition ist ein Term eine Kombination aus Zahlen, Variablen und Rechenzeichen, die man ausrechnen kann. Wenn wir also schon wissen, dass eine Formel für alle Zahlen gilt, dann gilt sich auch für alle Terme, weil durch das Ausrechnen des Terms immer eine Zahl entsteht, für die die Formel ja schon gültig ist.
Dieser Zusammenhang führt zu der Frage: Wissen wir denn, welche Terme es gibt? Also, wenn wir sagen, man könne alle Terme einsetzen, wäre es doch vielleicht ganz interessant zu wissen, welche Terme es überhaupt gibt. Um es kurz zu machen: In der Mathematik werden ständig neue Terme gefunden bzw. erfunden. (Anmerkung: Sogar die Frage: „Werden Terme erfunden oder gefunden?“, lässt sich nicht grundsätzlich klären.) Deshalb können wir nicht wissen, welche Terme es gibt.
Mit dieser Antwort könnte man sich zufrieden geben – oder weiterfragen: Aber wenn Terme doch definiert sind als etwas, was man ausrechnen kann, dann führen Terme doch immer zu Zahlen, unabhängig davon, ob wir alle Terme kennen, oder nicht?
Mögliche Antwort: Nicht alle Ergebnisse von Rechnungen sind Zahlen.
Frage 6: Was wäre, wenn das Kommutativgesetz nicht gelten würde? Hätten wir dann eine andere Mathematik? Würde das zu Widersprüchen führen? Was wäre das Problem?
Mögliche Antwort: Man könnte die Addition so ähnlich wie die Züge eines Springers auf dem Schachbrett definieren. Dann könnte \(3+4\) bedeuten: Erst \(3\) Felder nach rechts und dann \(4\) Felder nach oben. Und wenn dann \(4+3\) bedeutet, erst \(4\) Felder nach rechts und dann \(3\) Felder nach oben zu gehen, ist die Addition nicht kommutativ.
Warum ist Minus mal Minus gleich Plus?

Die Festlegung, dass Minus mal Minus gleich Plus ist, also dass z. B. \( -2 \cdot (-3) = + \; 6 \) ist, ist Ausgangspunkt vieler mehr oder weniger ernsthafter Diskussionen über die Richtigkeit der Mathematik. Das ist verständlich, widerspricht dieses „Minus mal Minus“ doch dem Verständnis der Multiplikation, wie wir sie seit der Grundschule kennen. Damals haben wir gelernt: Die Multiplikation ist eine Abkürzung der Addition. Z. B. ist \(3 \cdot 4\) entweder \(3 + 3 + 3 + 3\) oder \(4 + 4 + 4\). In diesem Zusammenhang ergibt ein Ausdruck wie \( (-3) \cdot (-4) \) einfach keinen Sinn.
Das Problem liegt in der Tat sehr tief: Wir können nämlich nicht beweisen, dass „Minus mal Minus“ an sich und überhaupt gleich „Plus“ sein muss. Wir können aber an bestimmten mathematischen Modellen zeigen, wie solche Rechnungen sinnvoll sind und auch zu richtigen Ergebnissen führen. Im folgenden PDF geht es zum einen um die Zahlengerade als Standardmodell der Mathematik für das Rechnen mit Zahlen und zum anderen um zwei Modelle, die mehr mit dem Alltag zu tun haben: Es geht um das Hin- und Herlaufen und um das Essen von Schokoladenkeksen. Ja, auch für Schokoladenkekse ist „Minus mal Minus“ gleich „Plus“!
In diesem Video wird eine andere Erklärung gezeigt: Es geht darum, dass jede Zahl eine Gegenzahl haben soll. Die Gegenzahl einer negativen Zhl muss dann eine positive Zahl sein.
Weitere Fragen
Nicht nur die Multiplikation zweier negativer Zahlen muss begründet werden, sondern auh die Multiplikation mit \(1\) oder \(0\).
Die Menge der natürliche Zahlen \(\mathbb{N}\) ist die Menge \({1; 2; 3; 4; \dots}\). (In manchen Teilgebieten der Mathematik wird auch die \(0\) zu den natürlichen Zahlen gezählt.) In der Grundschule haben wir die Multiplikation natürlicher Zahlen als Abkürzung der Addition kennengelernt. Es ist z. B. \(3 \cdot 4\) entweder gleich \(4+4+4\) oder gleich \(3+3+3+3\).
Frage 1: Es ist festgelegt, dass \(1 \cdot 4 = 4\) ist. Dabei wird \(4\) aber nicht einmal addiert, sondern gar nicht. Außerdem ist festgelegt, dass \(0 \cdot 4 = 0\) ist. Auch dabei wird \(4\) gar nicht addiert; es kommt aber nicht \(4\), sondern \(0\) heraus. Wie kann man das erklären? Ist das sinnvoll? Hätte es Vorteile, die Ergebnisse anders festzulegen?
Frage 2: Wenn man Mathematik macht, kann man den Eindruck haben, Mathematik sei so, wie sie ist, weil sie so sein muss. Nun ist aber in Frage 1 davon die Rede, die Multiplikation mit \(1\) und auch die Multiplikation mit \(0\) sei festgelegt. Aber muss man das festlegen? Oder gibt es eine Argumentation, nach der die Ergebnisse so sein müssen? Kann man die Ergebnisse auch anders festlegen? Wie sähe dann die Mathematik aus? (Didaktische Anmerkung: Auch wenn es für viele Menschen ungewöhnlich klingt: Auf diese Fragen gibt es tatsächlich keine Standardantworten! Spricht man mit Mathematikern darüber, kommt man schnell auf Axiome – von denen manche Mathematiker glauben, sie müssten so sein und andere glauben, sie seien festgelegt.)
Termumformungen

An Termumformungen kann man sehr schön sehen, wie sich die Bedürfnisse Hochbegabter von denen anderer Schüler unterscheiden. Während die meisten Schüler so gut es geht das nachmachen, was an Termumformungen an der Tafel gestanden hat, stellen Hochbegabte Fragen, die für die meisten Mitschüler grotesk wirken. Manche dieser Fragen können mitunter sogar Mathelehrer nicht beantworten. Z. B.: Was ist ein Term? Was ist eine Termumformung? Wird bei einer Termumformung ein bestehender Term in einen anderen umgeformt oder wird zu einem bestehenden Term ein weiterer gefunden? Was ist eine richtige Termumformung und warum? Wie kann man den Grund für die Richtigkeit intuitiv verstehen? Wie kann man die Ergebnisgleichheit zwei Terme für alle Zahlen nachweisen, obwohl es unendlich viele Zahlen gibt? Warum macht man überhaupt Termumformungen?
Im nachfolgenden PDF werden zwar nicht alle Fragen vollständig beantwortet. Es werden aber ein paar Wege gezeigt, die man gehen könnte, um ein tiefes Verständnis von Termen zu erlangen.
Weitere Fragen
Frage 1: Es gibt grundsätzlich zwei Möglichkeiten, die Frage, was eine Termumformung eigentlich ist, zu beantworten.
1) Ein gegebener Term wird verändert. Man hat also vor der Umformung einen einzigen Term und nach der Umformung hat man denselben Term, der aber jetzt anders aussieht.
2) Zu einem gegebenen Term wird ein weiterer, ergebnisgleicher Term gefunden. Man kann sich dabei vorstellen, zu dem gegebenen Term gebe es eine Menge, die alle Terme enthält, die zu diesem Term ergebnisgleich sind. Aus dieser Menge wählt man dann einen passenden Term aus.
Es ist in der Mathematik tatsächlich nicht geklärt, welche Ansicht die „richtige“ ist. Wenn man sich also mit diesen Fragen beschäftigt, ist es ziemlich wahrscheinlich, dass man dabei neue Mathematik findet.
Frage 2: Wenn man Termumformungen durchführt, geht es meist darum, Terme zu vereinfachen. Aber kann man denn immer klären, welcher Term der einfachste ist? Was soll eigentlich „einfach“ heißen? Was bedeutet es, wenn der eine Term einfacher ist als der andere?
Frage 3: Gibt es Terme, die zwar ergebnisgleich sind, wobei aber der eine nicht in den anderen umgeformt werden kann? Der Stand der Mathematik dazu ist: Vermutlich gibt es diese Terme in dem elementaren Bereich, in dem wir uns hier bewegen, nicht. Aber ganz sicher ist das nicht. Wenn wir überhaupt nicht festlegen wollen, wie die Terme, die ergebnisgleich sind, strukturiert sein sollen oder wie sie entstehen oder wo sie herkommen sollen, dann wissen wir auch nicht, welche Terme in der Menge aller zu einem gegebenen Term ergebnisgleichen Terme enthalten sind.
Frage 4: Es gibt Terme, deren Ergebnis immer gleich 3 ist. Wie kann man zeigen, welche Terme in dieser Menge sind?
Frage 5: Gibt es eine Möglichkeit, die Komplexität von Termen zu numerieren? Man könnte z. B. festlegen, dass der Term \(a\) die Nummer \(0\) hat, weil er in der einfachsten Form vorliegt. Der ergebnislgeiche Term \(a+0\) könnte die Nummer \(1\) haben, weil man eine Termumformung braucht, um den Term in die einfachste Form zu bringen. Wie könnte man weiter vorgehen?
Frage 6: Eine weitere Möglichkeit, die Komplexität von Termen zu beurteilen (und so vielleicht die Gültigkeit von Termumformungen in einer geordneten Weise untersuchen zu können), ist, die Anzahl der Zeichen zu zählen. Man merkt dann aber schnell, dass ein Term wie \(0+0+0+ \dots \) zwar viele Zeichen haben kann, aber dennoch nicht als besonders Komplex empfunden wird. Trotzdem kann man auf die Betrachtung der Anzahl der Zeichen wohl auch nicht verzichten, weil z. B. Terme, die nur aus einem einzigen Zeichen bestehen, nicht besonders komplex sein können. Was kann man tun?
Äquivalenzumformungen verstehen

Genauso wie Termumformungen kann man sich Äquivalenzumformungen an der Zahlengerade verständlich machen. Interessanterweise ist das viel komplizierter als Äquivalenzumformungen auszuführen. Dieses Phänomen können wir bei vielen mathematischen Zusammenhängen beobachten und es macht einen Teil der Stärke der Mathematik aus: Jeder Mensch kann Mathematik anwenden, indem er Zahlen in eine Formel einsetzt, ohne die Begründung der Formel verstehen zu müssen. Allerdings ist der Teil der Mathematik, in dem man sich um das Verständnis bemüht, der weitaus interessantere Teil.
pq-Formel für quadratische Gleichungen
Die pq-Formel ist eine wichtige Formel, mit der quadratische Gleichungen gelösten werden können. Im Video schauen wir uns die Formel an, aber nicht, wie sie hergeleitet werden. Es werden außerdem mehrere Beispiele durchgerechnet, in denen die pq-Formel angewendet wird. Wir stellen fest, dass manche quadratischen Gleichungen zwei Lösungen haben und dass es auch quadratische Gleichungen gibt, die nur eine Lösung oder auch gar keine Lösung haben. In diesem Video werden nicht nur die Rechnungen gezeigt, sondern es wird auch darauf eingegangen, wie man feststellen kann, ob auf eine gegebene Gleichung die pq-Formel überhaupt anwendbar ist. Es gilt: Die pq-Formel ist anwendbar, wenn durch die Ersetzung von p und q durch Zahlen in der Normalform einer quadratischen Gleichung die gegebene Gleichung ensteht. Da dieser Satz aber sehr umständlich klingt, wird im Video gar nicht weiter darauf eingegangen, sondern es wird einfach der Ersetzungsprozess anschaulich durchgeführt. So kann man auch sehen, welche Klammern für den Fall „mitgenommen“ werden müssen, wenn in der gegebenen Gleichung negative Zahlen vorkommen. Selbstverständlich ensprechen auch in diesem Video alle Formulierungen und Notationen dem in der Mathematik gängigen exakten Sprachgebrauch. Das können Menschen, die die bei YouTubern übliche Schludrigkeit gewohnt sind, als belastend empfinden. Alle, die wissen möchten, wie die Rechnungen „offiziell“ gesprochen und aufgeschrieben werden, werden hier fündig werden.
Exponentialfunktion mit Salzteig
Exponentialfunktionen kommen im Alltag immer wieder vor. Wir sind quasi von diesen Funktionen umgeben. Um diese Tatsache mal sehr plastisch zu zeigen, wird in diesem Video eine Exponentialfunktion mit Salzteig vorgeknetet. Auch so können wir uns Exponentialfunktionen vorstellen. Und am Ende kommt noch ein Brüller: Wir sehen nämlich fast ganz von selbst, warum irgendetwas hoch 0 immer gleich 1 ist.
Warum ist \(2^0=1\) ?

So, wie die Multiplikation als Abkürzung der Addition eingeführt wird – z. B. ist \(2+2+2=3 \cdot 2\) -, wird das Potenzieren zunächst als Abkürzung der Multiplikation erklärt, wobei z. B. \(2 \cdot 2 \cdot 2 = 2^3\) ist. Und solange die Basen und Exponenten positive natürliche Zahlen sind, ist das auch kein Problem. Aber schon bei \(2^1\) kann man in Grübeln kommen. Man hat festgelegt, dass \(2^1=2\) ist. Das passt immerhin zur Definition der Multiplikation, weil \(2=1 \cdot 2\) ist. Setzt man hingegen als Exponent \(0\) ein, muss man sich fragen, was \(2^0\) bedeuten soll. Nun, es ist \(2^0=1\), genauso, wie \(22^0=1\) und \( \left( \frac{1}{222} \right)^0 =1\) ist. Das kommt vielen Menschen sehr merkwürdig vor. Im folgenden PDF wird erklärt, warum das so festgelegt wurde und warum diese Festlegung sogar Sinn ergibt.
Differential- und Integralrechnung
Ableitung ohne Grenzwert
Der Differentialquotient ist der zentrale Begriff der Differentialrechnung. In diesem Video sehen wir uns an, wie wir anschaulich verstehen können, was der Differentialquotient bedeutet. Geometrisch gesehen geht es darum, die Steigung einer Tangente zu bestimmen, die den Graphen einer Funktion in einem Punkt berührt. Das Problem dabei ist, dass wir für die Steigungsbestimmung von Geraden – und eine Tangente ist ja eine Gerade – zwei Punkte brauchen, wobei die Tangente aber nur einen einzigen Punkt mit dem Funktionsgraphen gemeinsam hat. Normalerweise wird dieses Problem dadurch gelöst, dass die Tangentsteigung als Grenzwert der Sekantensteigungen definiert wird. In diesem Video gehen wir aber einen ganz anderen Weg: Wir sehen uns an, welche Steigungen die Sekanten haben, die sich in der Umgebung des Berührpunktes befinden. Wir stellen dann fest, dass es nur eine einzige Steigung gibt, die keine Sekantensteigung ist: Es ist die Tangentensteigung. Wir bestimmen also die Tangentensteigung, indem wir alle anderen Steigungen ausschließen. Dabei kommen wir sogar ohne den Grenzwertbegriff aus.
Weitere Fragen
Der „Trick“ bei der Ableitung ohne Grenzwert ist die Beantwortung der Frage, was ein Grenzwert eigentlich ist. In der Schule geht man normalerweise davon aus, dass der Grenzwert derjenige Wert sei, zu dem etwas hin strebt. Im Video geht man aber von einer anderen Definition des Grenzwertes aus: Der Grenzwert ist die einzige Zahl, die durch die Annäherung nicht erreichbar ist.
Frage 1: Welche Vor- und Nachteile haben beide Grenzwert-Definitionen?
Frage 2: Wie könnte man die Grenzwert-Definitionen formal exakt aufschreiben?
Frage 3: Kann man auf den Nachweis, dass die nicht zu erreichende Zahl die einzige ihrer Art ist, verzichten? Könnte es mehrere solcher Zahlen geben?
Wir können eine ähnliche Überlegung auch auf Folgen übertragen: Man sagt z. B., der Grenzwert der Folge \( \frac{1}{2} ; \frac{1}{3} ; \frac{1}{4} ; \dots \) – wobei die Folge meist kurz als \( \big{\langle}\frac{1}{n} \big{\rangle}_{n \in \mathbb{N}}\) bezeichnet wird – sei gleich \(0\), weil die Folgenglieder sich immer mehr der \(0\) annäherten. Der Einwand, der in diesem Zusammenhang häufig erhoben wird, ist: Wie kann man sicher sein, dass \(0\) tatsächlich der Grenzwert ist, wenn die Folge diese Zahl doch nie erreicht? Eine Lösung kann darin liegen, den Grenzwert anders zu definieren: In diesem Fall könnte der Grenzwert die größte Zahl sein, die kleiner als alle Folgenglieder ist. Man sagt dann auch, diese Zahl sei die größte untere Schranke.
Frage 4: Arbeite diese Idee des Grenzwerts aus. Für welche Prozesse ist ein solcher Grenzwert aus deiner Sicht vorteilhaft?
Potenzregel – Herleitung
Die Potenzregel braucht man für das Ableiten von Potenzfunktionen und damit auch für alle ganzrationalen Funktionen. Wie in der Mathematik üblich, wird die Regel erst bewiesen, bevor sie angewendet wird. Der Beweis für natürliche Exponenten kann über das Ausmultiplizieren eines Binoms erfolgen. Die Potenzregel gilt aber für alle reellen Exponenten (was im Schulstoff meist unterschlagen wird). Für den allgemeinen Beweis braucht man zwar die Kettenregel und die Ableitung der Logarithmusfunktion, man muss aber auch viel weniger schreiben.
Kettenregel – Herleitung und anschauliche Erklärung
Mit der Kettenregel leiten wir verkettete Funktionen ab. Im Video wird die Kettenregel vorgestellt, ein Beispiel wird vollständig vorgerechnet, die formale Begründung wird gezeigt und wir sehen uns auch an, wie wir die Kettenregel anschaulich verstehen können. Dabei ist zu begründen, warum das Produkt der Ableitungen von innerer und äußerer Funktion ausgerechnet gleich der Steigung der verketteten Funktion ist. Außerdem überlegen wir uns, warum die Ableitungen multipliziert und nicht etwa addiert werden.
Hauptsatz der Differential- und Integralrechnung
Wenn man so will, behauptet der Hauptsatz der Differential- und Integralrechnung, dass (unter bestimmten Umständen) die Ableitung einer Flächeninhaltsfunktion exakt gleich den Funktionswerten der Funktion ist, deren Fläche zwischen Graph und x-Achse sie misst. Noch einfacher gesagt: Die Flächenbestimmung ist das Gegenteil der Steigungsbestimmung und umgekehrt. Das darf man ruhig verwunderlich finden! Der formale Beweis des Hauptsatzes ist zwar kurz, er gibt aber nichts intuitiv Verstehbares zu diesem Zusammenhang preis. Deshalb steht im PDF eine anschauliche Begründung für die Tatsache, dass (unter bestimmten Umständen) das Integrieren das Gegenteil des Ableitens ist.
Unter bestimmten Umständen kann man den Hauptsatz der Differential- und Integralrechnung (etwas verkürzt) so verstehen: Man kann mit einer Stammfunktion eine Fläche berechnen.* Nun hat aber eine Stammfunktion quasi als Gegenteil einer Ableitung erstmal nichts mit einer Fläche zu tun. Trotzdem funktioniert es. Wie wir diesen Zusammenahng anschaulich verstehen können, siehst du im Video.
*(Genauer gesagt: Man kann die Fläche zwischen dem Graphen einer Funktion f und der x-Achse auf dem Intervall [a; b] durch die Differenz der Funktionswerte F(b) und F(a) einer Stammfunktion F bestimmen.)
Uneigentliche Integrale

Mit den uneigentlichen Integralen bringt man das Kunststück fertig, eine unendlich breite Fläche vor sich zu haben, die aber nur einen endlichen Flächeninhalt hat. Das rebelliert normalerweise unser gesunder Menschenverstand. Umso überraschender ist, dass es eine extrem einfache Erklärung gibt, mit der wir dieses scheinbar widersprüchliche Phänomen verstehen können.
Weitere Fragen
Im Zusammenhang mit den uneigentlichen Integralen geht es um zwei verschiedene Prozesse. Zum einen lässt sich die grüne Fläche unter der Kurve verstehen als Fläche, zu der unendlich oft etwas addiert wird, zum anderen gibt es eine begrenzte graue Fläche, die auf eine unendliche Breite verteilt wird. Gibt es solche Prozesse auch in anderen mathematischen oder nicht-mathematischen Zusammenhängen? Gibt es vielleicht zu jeder Summe mit unendlich vielen Summanden deren Ergebnis endlich ist eine endliche Größe, die auf die Summanden verteilt werden können? Oder einfacher gefragt: Muss es zu dem einen Prozess immer auch den anderen Prozess geben?
Im Text ist die Fläche des grauen Quadrats größer als als die gesamte grüne Fläche. Geht das auch mit einer grauen Fläche, die kleiner als die gesamte grüne Fläche ist? Und wenn ja: Wie groß ist der Unterschied dieser beiden grauen Flächen? Kann man den Unterschied verkleinern? Kann man ihn auf \(0\) senken?
Es ist \(\frac{1}{3}=0,\bar 3\). Dabei können wir \(0,\bar 3\) verstehen als \(0,3 + 0,03 + 0,003 + 0,0003 + \dots\). Das ist eine Summe, die trotz unendlich vieler Summanden nicht unendlich groß wird.
Die Summe \( \frac{1}{2} + \frac{1}{3} + \frac{1}{4} + \frac{1}{5} + \dots \) wächst über alle Grenzen, obwohl die Summanden immer kleiner werden. Daraus ergibt sich z. B. die Frage, wie „schnell“ Summanden kleiner werden müssen, damit die Summe nicht über alle Grenzen wächst. Interessanterweise gibt es in der Mathematik bisher keine Möglichkeit, diese Frage für alle Summen zu beantworten.
Die hier gestellten Fragen gehören zum Thema „Konvergenz von Reihen“.
Wahrscheinlichkeitsrechnung und Statistik
Was ist Wahrscheinlichkeit?
In der Schule werden vor allem zwei unterschiedliche Wahrscheinlichkeitsbegriffe gelehrt: Der Laplacesche Wahrscheinlichkeitsbegriff und der frequentistische Wahrscheinlichkeitsbegriff. Mit beiden gibt es erhebliche Verständnisprobleme – mal abgesehen davon, dass sie laut Zeitschrift „mathematik lehren“ auch zirkulär sind. Es gibt aber einen sehr einfachen Wahrscheinlichkeitsbegriff, der entsteht, wenn man die axiomatische Wahrscheinlichkeit auf Schulniveau herunterbricht: Wahrscheinlichkeiten sind Anteile. Zudem kann man sich die Diskussion, ob dies die „richtige“ Wahrscheinlichkeit sei oder nicht, sparen: Wir rechnen ohnehin mit Anteilen, egal, ob wir die Wahrscheinlichkeit beim Lose-Ziehen ausrechnen oder sie über die Integration einer Dichtefunktion bestimmen.
Regenwahrscheinlichkeit
Im Wetterbericht kann man Sätze hören wie: „Die Regenwahrscheinlichkeit beträgt heute 80%.“ Das Problem dabei ist: Das Wetter ist kein Zufallsversuch und deshalb kann es auch keine Regenwahrscheinlichkeit geben. Deshalb gehen wir im Video der Frage nach, was eine solche Regenwahrscheinlichkeit bedeutet könnte. Es bedeutet nicht, dass auf 80% der Fläche des Vorhersagegebietes Regen fallen wird und es heißt auch nicht, dass es 80% der Zeit regnen wird. Sondern: Es bedeutet, dass es in der Vergangenheit an 80% der Tage mit vergleichbarer Wetterlage geregnet hat. Damit ist die „Wahrscheinlichkeit“ tatsächlich also eine relative Häufigkeit. Wie man im Netz nachlesen kann, soll aber auch diese relative Häufigkeit nicht immer an die Zuschauer weitergegeben werden. Im Video geht es nun nicht um die Diskussion, ob das tatsächlich so ist oder nicht, sondern um eine mögliche Ursache: Diese ist die Verlustaversion, die man tatsächlich auch mathematisch erfassen kann.
Regel von Bayes – Veranschaulichung
Die Regel von Bayes ist deshalb etwas „merkwürdig“, weil auf der linken Seite der Formel eine Information steht, die – bei oberflächlicher Betrachtung – auf der rechten Seite gar nicht vorkommt. In dies
Empirisches Gesetz der großen Zahlen

Angenommen, wir haben eine Box mit einer blauen und einer roten Kugel. Wir ziehen zufällig eine Kugel, notieren uns die Farbe und legen die Kugel wieder zurück. Dann ziehen wir wieder eine Kugel usw. Wenn wir diesen Vorgang \( 100\)-mal durchführen, kann es gut sein, dass wir ca. \(50 \) blaue und ca. \( 50 \) rote Kugeln ziehen. Diese „Tatsache“ ist die Kernaussage des empirischen Gesetzes der großen Zahlen. Aber warum ist das so? Natürlich nicht deshalb, weil es die „Gesetze des Zufalls“ so wollen – wie manchmal etwas hochtrabend behauptet wird. (Und selbst wenn das so wäre, wäre damit die Frage nach dem „Warum?“ immer noch nicht beantwortet.) Die kürzest mögliche Antwort ist: Weil es viel mehr Möglichkeiten mit ca. \( 50 \) blauen Kugeln gibt als es andere Möglichkeiten gibt.
Im folgenden PDF ist die Lage ausführlich dargestellt. Es wird genau erklärt, was „viel mehr Möglichkeiten“ bedeutet und auch gezeigt, wie man dieses empirische Gesetz der großen Zahlen mit dem Galton-Brett verstehen kann. Außerdem wird gezeigt, wie man auch ohne das Wissen der Kombinatorik die Anzahlen der Möglichkeiten mit Hilfe (erweiterter) Pascalscher Dreiecke für die ersten Versuchsanzahlen ausrechnen kann.
Die im PDF gezeigte einzigartige Methode der Erklärung des empirischen Gesetzes der großen Zahlen hat den enormen Vorteil, dass die Gesetzmäßigkeiten direkt nach den ersten wenigen Versuchsdurchführungen intuitiv erkannt werden können. Hier kann also auf den sonst üblichen (verwirrenden) Hinweis, das empirische Gesetz der großen Zahlen gelte nur für ganz ganz viele Versuchsdurchführungen, verzichtet werden.
Die relative Häufigkeit und ein folgenreicher Irrtum
Ein weitverbreiteter Irrtum ist, die relative Häufigkeit eines Ereignisses nähere sich mit zunehmender Versuchsanzahl der Wahrscheinlichkeit dieses Ereignisses an. Zwar kann es gut sein, nach 100-maligem Münzwurf ungefähr 50-mal „Kopf“ zu erhalten (d.h. die relative Häufigkeit von „Kopf“ ist dann in der Nähe der Wahrscheinlichkeit von „Kopf“), es MUSS aber nicht so sein.
In diesem Video wird gezeigt, wie sehr das Verständnis der Wahrscheinlichkeitsrechnung unter diesem Irrtum leidet, wie das vermieden werden kann und wie es wirklich ist. Und es wird gezeigt, wie einfach die dahinterliegende Mathematik tatsächlich ist.
Weitere Fragen
Warum sich die relative Häufigkeit nicht der Wahrscheinlichkeit annähern muss
Dass sich die relative Häufigkeit eines Ereignisses der Wahrscheinlichkeit dieses Ereignisses annähern muss, wenn der Zufallsversuch „oft“ wiederholt wird, wird häufig (fälschlicherweise) als zentrale Aussage des empirischen Gesetzes der großen Zahlen angeführt. Dazu gibt es in viele Formulierungen, wobei manche falscher als andere sind. Völlig falsch ist die folgende Formulierung, die man auf den Seiten des Vereins MUED e. V. finden kann (wenn man Mitglied ist):
„Dieses berühmte Gesetz der Großen Zahl besagt, dass bei vielen unabhängigen Wiederholungen eines Zufallsexperiments, sei es Münzwurf, Würfeln, Lotto, Kartenspielen oder was auch immer, die relative Häufigkeit und die Wahrscheinlichkeit eines Ereignisses immer näher zusammenrücken müssen: Je häufiger wir eine faire Münze werfen, desto näher kommt der Anteil von ‚Kopf‘ seiner Wahrscheinlichkeit ein halb, je häufiger wir würfeln, desto näher kommt der Anteil der Sechsen der Wahrscheinlichkeit für Sechs, und je häufiger wir Lotto spielen, desto näher kommt die relative Häufigkeit der 13 der Wahrscheinlichkeit der 13. An diesem Gesetz gibt es nichts herumzudeuteln, dieses Gesetz ist in gewisser Weise die Krönung der gesamten Wahrscheinlichkeitstheorie.“Warum das so wichtig ist
Um es ganz kurz zu machen: Wenn dieses Gesetz in dieser Formulierung richtig wäre, gäbe es keinen einzigen (wiederholbaren) Zufallsversuch.
Kein Zufallsversuch
Ein Beispiel: Angenommen, wir werfen zufällig eine Münze, sodass wir die Ergebnisse Z (Zahl) und K (Kopf) erhalten können. Dabei sollen beide Ergebnisse jeweils die Wahrscheinlichkeit 0,5 haben. Nehmen wir weiter an, wir hätten die Münze 50-mal geworfen und hätten 50-mal Z erhalten. Dann war die relative Häufigkeit von Z nach der ersten Versuchsdurchführung gleich 1, nach der zweiten Versuchsdurchführung war sie ebenfalls gleich 1 und auch nach der dritten, vierten usw. In diesen ersten 50 Versuchsdurchführungen hat sich die relative Häufigkeit von Z also nicht der Wahrscheinlichkeit von Z angenähert.
Nun wird oft argumentiert, die Annäherung von relativer Häufigkeit und Wahrscheinlichkeit finde „auf lange Sicht“ oder auch bei „sehr vielen“ Versuchsdurchführungen statt. Aber was soll das bedeuten? Muss die Münze, wenn sie in den ersten 50 Versuchsdurchführungen zu oft Z angezeigt hat, bis zur 100-sten Versuchsdurchführung verstärkt K zeigen, damit sich das Verhältnis wieder ausgleicht? Oder muss sich die relative Häufigkeit erst bis zur 1000. Versuchsdurchführung der Wahrscheinlichkeit angenähert haben?
Wie wir es auch drehen und wenden: Wenn sich relative Häufigkeit und Wahrscheinlichkeit annähern müssen, darf das Ergebnis eines Münzwurfs irgendwann nicht mehr vom Zufall abhängen, sondern muss sich nach dem richten, was die Münze in den Versuchsdurchführungen davor angezeigt hat. Damit wäre der Münzwurf kein Zufallsversuch mehr. Man mag darüber streiten, was genau Zufall sein soll, aber mit Sicherheit gehört doch zu einem Zufallsversuch wie dem Münzwurf dazu, dass es eben kein Gesetz gibt, welches der Münze vorschreibt, was sie anzuzeigen hat.
Noch schlimmer wird die Lage, wenn im Anfangsunterricht der Stochastik behauptet wird, die Wahrscheinlichkeit eines Ereignisses sei die Zahl, zu der die relative Häufigkeit des Ereignisses strebt, wenn der Zufallsversuch oft genug wiederholt wird. Abgesehen davon, dass Schülern weder klar ist, was „streben“ oder „oft genug“ sein soll, können sie eine solche „Definition“ auch nicht mit ihrer Vorstellung von Zufall verbinden. Denn diese Herangehensweise führt zu der absurden Idee, dass irgendwer der Münze sagen muss, was sie zu machen hat oder dass die Münze ein Gedächtnis hat und selbst um den Ausgleich von relativer Häufigkeit und Wahrscheinlichkeit bedacht ist. Damit sind schon die grundlegenden Begriffe der Wahrscheinlichkeitsrechnung, nämlich Zufall und Wahrscheinlichkeit, derartig widersprüchlich, dass für Schüler ein Verständnis dieses Gebietes der Mathematik ausgeschlossen ist.
Überflüssige Statistik
Man kann in jedem Buch über die Einführung in die Wahrscheinlichkeitstheorie nachlesen, dass sich die relative Häufigkeit eines Ereignisses auch nach einer noch so großen Anzahl von Versuchsdurchführungen nicht an die Wahrscheinlichkeit des Ereignisses annähern muss. Alle statistischen Methoden, mit denen man von der relativen Häufigkeit auf die Wahrscheinlichkeit schließt, wären überflüssig, wenn sich die relative Häufigkeit der Wahrscheinlichkeit annähern müsste. Es gibt die „Konvergenz in Wahrscheinlichkeit“ und das schwache Gesetz der großen Zahlen nur deshalb, weil die relative Häufigkeit eines Ereignisses eben nicht analytisch gegen die Wahrscheinlichkeit des Ereignisses konvergiert. Warum aber trotzdem an deutschen Schulen falsche Mathematik unterrichtet wird, ist für mich persönlich nicht nachvollziehbar.
Was tatsächlich gilt
Es gilt das schwache Gesetz der großen Zahlen. Auf den obigen Fall angewendet bedeutet dieses Gesetz vereinfachend formuliert, dass sich die relative Häufigkeit nicht der Wahrscheinlichkeit annähern muss, sondern dass die Wahrscheinlichkeit der Annäherung steigt.
Etwas genauer: Wir können uns fragen, wie groß die Wahrscheinlichkeit ist, dass die relative Häufigkeit von Z in einem bestimmten Intervall um die Wahrscheinlichkeit von Z liegt. Da die Wahrscheinlichkeit von Z gleich 0,5 ist, können wir als Intervall z. B. (0,4; 0,6) festlegen. Die Wahrscheinlichkeit, dass die relative Häufigkeit von Z in diesem Intervall liegt, wird nun mit steigender Anzahl der Versuchsdurchführungen immer größer.Eine Gegenargumentation
Stellen wir uns folgende Zufallsversuche vor: In einem Behälter befinden sich eine blaue und eine rote Kugel. Es wird eine Kugel zufällig gezogen, die Frabe notiert und die Kugel wieder zurück gelegt. Danach wird wieder eine Kugel zufällig gezogen usw.
Ist beim ersten Versuch eine rote Kugel gezogen worden, so ist die Wahrscheinlichkeit, beim zweiten Versuch eine rote Kugel zu ziehen, genauso groß wie beim ersten Versuch, nämlich 0,5. Das gilt auch für andere Versuchsanzahlen: Sind z. B. nach 99 Versuchen 99 rote Kugeln gezogen worden, ist die Wahrscheinlichkeit, beim 100. Versuch wieder eine rote Kugel zu ziehen, immer noch gleich 0,5. Und das gilt auch, wenn vorher 99 blaue Kugeln gezogen wurden oder wenn irgendeine andere Kombination blauer und roter Kugeln gezogen wurde.
Das bedeutet, die Wahrscheinlichkeit, 100 mal rot zu ziehen, ist genauso groß wie die Wahrscheinlichkeit, irgendeine andere Kombination aus blauen und roten Kugeln zu ziehen. Deshalb kann die relative Häufigkeit roter Kugeln nach 100 Versuchen bei 1 liegen. Damit ist sie maximal weit von der Wahrscheinlichkeit für rot entfernt und liegt nicht in der Nähe von 0,5. Die gleiche Argumentation gilt auch für 1 000, für 10 000 und für jede andere Anzahl von Versuchen. Es gibt also keine noch so große Anzahl von Versuchen, für die gilt: Die relative Häufigkeit der roten Kugeln muss in der Nähe von 0,5 liegen. Deshalb muss sich auch nicht die relative Häufigkeit der roten Kugeln bei zunehmender Anzahl der Versuchsdurchführungen der Wahrscheinlichkeit, eine rote Kugel zu ziehen, annähern.Das empirische Gesetz der großen Zahlen ist nicht von Bernoulli
Es wird behauptet, Jakob Bernoulli (1654 – 1705) habe das empirische Gesetz der großen Zahlen als erster formuliert. Das ist aber nicht richtig – zumindest dann, wenn man die gängigen Formulierungen berücksichtigt. Bernoulli schrieb z. B. nicht, die relativen Häufigkeiten eines Ereignisses A pendelten sich bei hinreichend großer Anzahl n der Versuchswiederholungen bei der Wahrscheinlichkeit von A ein. Ebensowenig schrieb er, die relativen Häufigkeiten eines Ereignisses A stabilisierten sich mit zunehmender Anzahl der Versuchsdurchführungen bei der Wahrscheinlichkeit von A und er schrieb auch nicht, die relativen Häufigkeiten von A müssten sich mit zunehmender Anzahl der Versuchsdurchführungen der Wahrscheinlichkeit von A annähern.
Und hier ist – in der deutschen Übersetzung – das, was Bernoulli tatsächlich schrieb:
„Satz: Es möge sich die Zahl der günstigen Fälle zu der Zahl der ungünstigen Fälle genau oder näherungsweise wie , also zu der Zahl aller Fälle wie \( \frac{r}{r+s}=\frac{r}{t} \) – wenn \( r+s=t \) gesetzt wird – verhalten, welches letztere Verhältniss zwischen den Grenzen \( \frac{r+l}{t} \) und \( \frac{r-l}{t} \) enthalten ist. Nun können, wie zu beweisen ist, soviele Beobachtungen gemacht werden, dass es beliebig oft (z. B. c-mal) wahrscheinlicher wird, dass das Verhältniss der günstigen zu allen angestellten Beobachtungen innerhalb dieser Grenzen liegt als ausserhalb derselben, also weder grösser als \( \frac{r+l}{t} \) , noch kleiner als \( \frac{r-l}{t} \) ist.“ (Bernoulli 1713, S. 104), in der Ausgabe: Wahrscheinlichkeitsrechnung (Ars conjectandi), Dritter und vierter Theil, übersetzt von R. Haussner, Leipzig, Verlag von Wilhom Engelmann, 1899)
Das, was Bernoulli schrieb, ist übrigens richtig und kommt dem schwachen Gesetz der großen Zahlen sehr nahe.Rechnerisch unmöglich
Es sind beliebig viele Situationen denkbar, in denen die relative Häufigkeit eines Ereignisses sich nicht der Wahrscheinlichkeit dieses Ereignisses nähert, sondern sich von diesem entfernt.
Ein Beispiel: Angenommen, wir werfen zufällig eine Münze, sodass wir die Ergebnisse Z (Zahl) und K (Kopf) erhalten können. Dabei sollen beide Ergebnisse jeweils die Wahrscheinlichkeit 0,5 haben. Nehmen wir weiter an, wir hätten die Münze 100-mal geworfen und 50-mal Z sowie 50-mal K erhalten. Dann ist die relative Häufigkeit von Z gleich 0,5. Wenn wir nun die Münze nochmals werfen, erhalten wir entweder Z – dann ist die relative Häufigkeit von Z gleich \(0,\overline{5049}\) – oder wir erhalten K – dann ist die relative Häufigkeit von Z gleich \(0,\overline{4851}\). In beiden Fällen entfernt sich die relative Häufigkeit Z wieder von der Wahrscheinlichkeit von Z. Wir können, nachdem wir beim Versuch Nummer 101 das Ergebnis Z erhalten haben, bei nachfolgenden Versuchsdurchführungen immer wieder Z erhalten. Die relativen Häufigkeiten für Z sind dann:
\(\approx 0,5098\), \(\approx 0,5146\), \(\approx 0,5192\), \(\approx 0,5283\), usw.
Damit rückt also die relative Häufigkeit von Z immer weiter von der Wahrscheinlichkeit von Z ab, was dem angeblichen Gesetz der großen Zahlen widerspricht.Ungewöhnliche Folgen
Das empirische Gesetz der großen Zahlen wird oft damit begründet, dass zwar auch ungewöhnliche Ergebnisse vorkommen können, die seien aber so unwahrscheinlich, dass sie praktisch nie vorkommen. Z. B. sei beim 30-fachen Münzwurf das Ergebnis KKKKKKKKKKKKKKKKKKKKKKKKKKKKKK sehr ungewöhnlich und auch unwahrscheinlich, während das Ergebnis KZZKZKKKZKZZKZZZKKKZKZKKKZZZZK viel normaler und deshalb wahrscheinlicher sei.
Das ist nicht nur deshalb falsch, weil beide Ergebnisse genau die gleiche Wahrscheinlichkeit haben, sondern auch deshalb, weil wir Menschen das, was an bestimmten Ergebnissen ungewöhnlich sein soll, in die Ergebnisse hineinfantasieren. Anders gesagt: Die Münze „weiß“ nichts von ungewöhnlichen Ergebnissen. Schauen wir uns dazu ein Beispiel an:

Angenommen, wir haben 10 Kugeln mit den Ziffern von 0 bis 9. Die Kugel mit der 0 ist grün, alle anderen sind gelb. Wir ziehen zufällig zehnmal mit Zurücklegen und mit Reihenfolge.
Achteten wir nur auf die Farben, empfänden wir das Ergebnis

vermutlich nicht als ungewöhnlichn. Käme dann aber bei der Betrach-tung der Zahlen das hier zum Vorschein

gälte die Stichprobe aber wohl doch als ungewöhnlich.
Wenn wir wollen, können wir aber noch ganz andere Maßstäbe ansetzen: Eine Stichprobe soll als ungewöhnlich gelten, wenn die Ziffernfolge in den ersten Nachkommastellen von π vorkommt. Die Stichprobe
ist gewöhnlich, weil sie nicht einmal unter den ersten 200 Millionen Nachkommastellen von π vorkommt. Die Stichprobe

ist ungewöhnlich, weil sie an Position 3 794 572 vorkommt. Die Stichprobe

kommt sogar an Position 851 vor und ist damit quasi extrem ungewöhnlich.
Egal ob ungewöhnlich oder nicht: Die Wahrscheinlichkeit jeder Stichprobe ist exakt die gleiche, nämlich: \[\frac{1}{10\,000\,000\,000}\]Was tatsächlich gilt
Schauen wir uns ein Beispiel dazu an: Wir ziehen zufällig eine Kugel aus einem Behälter, in dem sich zwei Kugeln befinden. Eine Kugel ist blau, die andere ist rot. Wir ziehen mehrmals mit Zurücklegen und mit Reihenfolge.

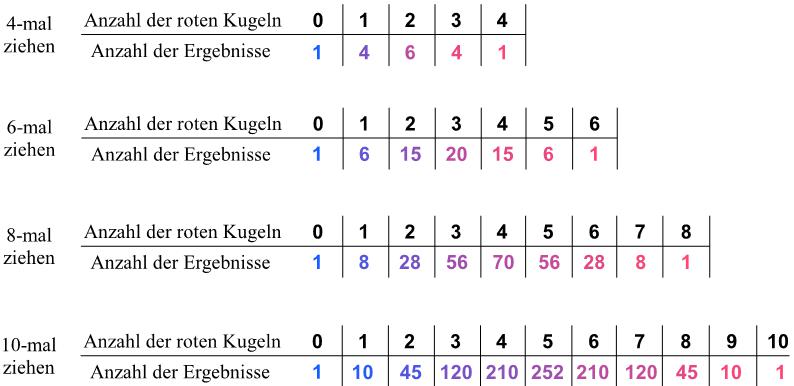
Wir wollen uns im Weiteren für die Anzahlen der roten Kugeln interessieren. In den folgenden Tabellen sind diese Anzahlen in Abhängigkeit von den Versuchsdurchführungen aufgelistet. Beim 8-maligen Ziehen gibt es z. B. 56 Ergebnisse mit 3 roten Kugeln.
Diese Anzahlen werden von den folgenden Säulendiagrammen maßstabsgetreu dargestellt. Wie wir sehen, wachsen mit zunehmender Anzahl der Versuchsdurchführungen die Anzahlen der Ergebnisse in der Mitte viel schneller als am Rand. Je öfter wir den Versuch durchführen, desto größer werden die Unterschiede zwischen der Mitte und dem Rand.
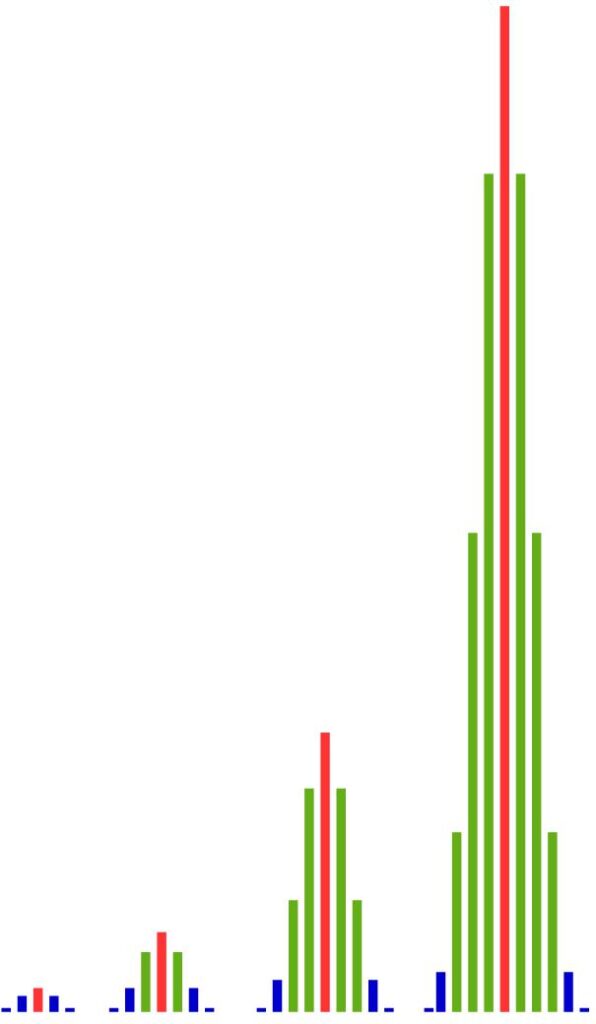
Das heißt: Es gibt einfach viel mehr Ergebnisse mit ungefähr 50 % roten Kugeln als es Ergebnisse mit viel weniger oder viel mehr roten Kugeln gibt. Und der Anteil der Ergebnisse in der Nähe der Mitte wird immer größer, je größer die Anzahl der Versuchsdurchführungen ist.
Dieses Phänomen können wir auch mit anderen Anteilen roter Kugeln in der Grundgesamtheit beobachten: Sind in der Grundgesamtheit zwei Drittel der Kugeln rot, sehen wir eine Häufung der Ergebnisse mit zwei Dritteln roter Kugeln.
Was wir hier sehen, können wir zwar etwas vereinfachend – aber nicht falsch – mit folgendem Satz zusammenfassen: Die relativen Häufigkeiten roter Kugeln sind in den meisten Ergebnissen so ähnlich wie die Wahrscheinlichkeit, eine rote Kugel zu ziehen.
Mit den Begriffen der Statistik hört sich das so an: Die meisten Stichproben sind so ähnlich wie die Grundgesamtheit.
Wenn wir also eine Münze 100-mal werfen und wir ca. 50-mal K erhalten, liegt das nicht daran, dass sich die relative Häufigkeit stabilisiert oder die Münze auf einen Ausgleich zwischen K und Z bedacht ist oder daran, dass eine dunkle Macht den Fall der Münze beeinflusst, sondern schlicht und ergreifen daran, dass es viel, viel mehr Ergebnisse gibt, die ca. 50-mal K enthalten als es Ergebnisse gibt, die viel weniger oder viel mehr K enthalten
Schwaches Gesetz der großen Zahlen

Das empirische Gesetz der großen Zahlen gibt es in der richtigen Mathematik nicht, weil dieses Gesetz vielleicht einer gewissen Erfahrung Audruck verleiht, aber keine beweisbare Aussage enthält . Das Gesetz aus der richtigen Mathematik, welches dem empirischen Gesetz der großen Zahlen vielleicht am nächsten kommt, ist das schwache Gesetz der großen Zahlen. Es hat inhaltlich mit dem Verhältnis von relativer Häufigkeit eines Ereignisses und der Wahrscheinlichkeit dieses Eriegnisses bei vielen Versuchsdurchführungen zu tun. Fälschlicherweise wird dieser Zusammenhang oft so beschrieben: Die relative Häufigkeit eines Ereignisses kommt der Wahrscheinlichkeit dieses Ereignisses immer näher, je häufiger der Zufallsversuch durchgeführt wird. Aber das stimmt nicht, denn das würde z. B. für den mehrfachen Münzwurf bedeutet: Wenn wir nach \(50\) Münzwürfen genau \(25\)-mal Kopf und genau \(25\)-mal Zahl geworfen haben, könnten wir danach nicht \(5\)-mal hintereinander Kopf werfen, weil sich dadurch die relative Häufigkeit des Ereignisses Kopf von dem Wert \(50\) % entfernen würde. So müsste also eine dunkle Macht unsere Hand führen um zu viele Kopf-Würfe zu vermeiden.
Umgangssprachlich (und richtig) formuliert besagt das schwache Gesetz der großen Zahlen: Die Wahrscheinlichkeit, dass die relative Häufigkeit eines Ereignisses in der Nähe der Wahrscheinlichkeit dieses Ereignisses liegt, wird immer größer, je häufiger der Zufallsversuch durchgeführt wird (und sie konvergiert sogar gegen \(1\), falls der Zufallsversuch unbegrenzt oft durchgeführt wird). In der Fachsprache nennt sich dieses Phänomen kurz „Konvergenz in Wahrscheinlichkeit“. Auf den Münzwurf übertragen bedeutet das: Je häufiger wir die Münze werfen, desto größer wird die Wahrscheinlichkeit, dass die relative Häufigkeit von Kopf in der Nähe der Wahrscheinlichkeit von Kopf – also in der Nähe von \(50\) % – liegt (und sie konvergiert sogar gegen \(1\), wenn der Münzwurf unbegrenzt oft durchgeführt wird).
Im folgenden PDF wird das schwache Gesetz der großen Zahlen möglichst einfach erklärt. Aber nicht einfacher! Es wird also mathematisch korrekt dargestellt, aber nur auf den möglichst einfachen Fall des Münzwurfs angewendet. Außerdem wird gezeigt, wie man sich dieses Gesetz anschaulich vorstellen kann und welche Fehlinterpretationen es gibt.
Starkes Gesetz der großen Zahlen

Wenn wir eine Münze immer wieder werfen und die Ergebnisse notieren, entsteht eine Ergebnisfolge wie z. B.
(Kopf, Kopf, Zahl, Kopf, Zahl, Zahl, Zahl, Kopf, … )
Das schwache Gesetz der großen Zahlen sagt etwas über eine solche Folge aus, nämlich wie sich die Wahrscheinlichkeit, dass sich die relative Häufigkeit von z. B. Kopf in der Nähe von \(0,5\) befindet, entwickelt, wenn der Münzwurf unbegrenzt oft durchgeführt wird. Das starke Gesetz der großen Zahlen hingegen sagt etwas über alle möglichen (unendlichen) Ergebnisfolgen, nämlich dass für (in einem bestimmten mathematischen Sinn) fast alle dieser Folgen gilt: Die relative Häufigkeit für z. B. Kopf konvergiert tatsächlich gegen \(0,5\), wenn der Münzwurf unbegrenzt oft durchgeführt wird. Der Begriff „fast“ ist in diesem Fall ein Fachbegriff. Er wird maßtheoretisch definiert.
Im folgenden PDF wird das starke Gesetz der großen Zahlen erklärt. Es geht dabei nicht um irgendeine weichgespülte umgangssprachliche Version dieses Gesetzes, sondern um das richtige Gesetz – allerdings wird es nur für den einfachst möglichen Fall – den Münzwurf – erklärt. Alle formalen Notwendigkeiten wie z. B. die Mittelwerte zentrierter Zufallsvariablen, werden im Text erklärt. Alles, was nicht absolut unverzichtbar ist, wird weggelasen. Außerdem wird noch auf die üblichen Fehlinterpretationen eingegangen und diese richtiggestellt.
Stochastische Unabhängigkeit – Anschauliche Erklärung
Die stochastische Unabhängigkeit zweier Ereignisse ist durch eine Formel definiert, die graphisch-optisch nicht viel hergibt. Um die Sache aber gefühlsmäßig-intuitiv zu verstehen, können wir auf die Anschauung zurückgreifen. Und da werden wir sehen, dass es bei der stochastischen Unabhängigkeit um die Beziehung zweier Mengen geht. Wenn diese Beziehung in gewisser Weise harmonisch ist, dann sind die Ereignisse stochastisch unabhängig. Genauer gesagt sind die Ereignisse A und B genau dann stochastisch unabhängig, wenn der Anteil von A an der Grundgesamtheit genauso groß ist wie der Anteil des Durchschnitts von A und B an B. Diese Sichtweise ist deshalb so wichtig, weil in Schulen immer wieder unterrichtet wird, für die stochastische Unabhängigkeit brauche man zwei Zufallsversuche. Das ist laut Formel aber nicht richtig, denn die Ereignisse A und B sind Teilmengen der Ergebnismenge ein und desselben Zufallsversuchs. Außerdem gibt es die Fehlvorstellung, die Eriegnisse A und B hätten nichts miteinander zu tun oder beeinflussten sich nicht gegenseitig, wenn sie stochastisch unabhängig seien. Aber grundsätzlich sind Ereignisse eines Zufallsversuchs Teilmeingen der Ergebnismenge, die einfach nur so da sind ohne sich aktiv irgendwie zu beeinflussen. Das können Ereignisse nämlich gar nicht.
Bedingte Wahrscheinlichkeit – einfache Erklärung
In diesem Video schauen wir uns zunächst die Formel an, mit der die bedingte Wahrscheinlichkeit definiert wird. Die Formel ist aber recht dürr und deshalb sehen wir uns noch ein Schaubild an, mit dem wir die bedingte Wahrscheinlichkeit viel plastischer zeigen können. So gelangen wir auch zu einer Formulierung der bedingten Wahrscheinlichkeit in „normalen“ Worten. Z.B.: Seien A und B Ereignisse eines Zufallsversuchs. Die Wahrscheinlichkeit von A unter der Bedingung B – in Zeichen P(A|B) – ist der Anteil von A in B. Alternative Formulierung: Die Wahrscheinlichkeit von A unter der Bedingnung B – in Zeichen P(A|B) – ist der Anteil der Wahrscheinlichkeit von A an der Wahrscheinlichkeit von B.
Zu dem Begriff „Bedingte Wahrscheinlichkeit“ gibt es viele Fehlvorstellungen, die sich leider hartnäckig halten. Es wird z. B. behauptet, man brauche zwei Zufallsversuche (oder zumindest zwei Handlungen innerhalb eines Zufallsversuchs), um bedingte Wahrscheinlichkeiten definieren zu können; dabei soll „die Wahrscheinlichkeit von A unter der Bedingung B“ dann die Wahrscheinlichkeit sein, mit der A eintritt, wenn B bereits eingetreten ist – oder, anders gesagt: die Wahrscheinlichkeit, dass beim zweiten Mal A eintritt, wenn schon bekannt ist, dass beim ersten Mal B eingetreten ist. Diese falsche Vorstellung macht es unmöglich, bestimmte Aufgaben zur bedingten Wahrscheinlichkeit lösen zu können. Z. B.: Ein einem Behälter befinden sich zwei schwarze und zwei weiße Kugeln. Es wird zweimal ohne Zurücklegen gezogen. Die Frage ist: Wie groß ist die Wahrscheinlichkeit, dass beim ersten Mal eine schwarze Kugel gezogen wird, unter der Bedingung, dass beim zweiten Mal eine weiße Kugel gezogen wird. Wenn man dabei die Vorstellung im Kopf hat, nur der erste Zug könne eine Bediungung für den zweiten Zug sein, wird man wohl davon ausgehen, die Aufgabe sei falsch gestellt. Schreibt man aber die Ergebnismenge mit allen möglichen ziehbaren Paaren auf und verfährt wie im Video gezeigt, löst sich dieser Widerspruch (bestimmt) auf.
5. Sonstiges
Standardmodell der Schulmathematik

Wir können uns Zahlen als Strecken auf der Zahlengerade vorstellen. Wir können sie aber auch vertikal aufstellen und so viele Zusammenhänge sehen, die man bei „liegenden“ Zahlen nicht sehen kann. Z. B. kann die Multiplikation von Brüchen oder das Potenzieren mit rationalen Exponenten an diesem Modell sehr gut verstanden werden.
Ortsvektor – Definition
Ein Ortsvektor ist nicht etwa ein Vektor, der sich an einem bestimmten Ort befindet, sondern ein Ortsvektor ist ein Vektor, der durch einen Ort definiert wird. Orte sind Punkte im Koordinatensystem. Legt man einen Ort fest, so gibt es nur einen einzigen Pfeil, der vom Koordinatenursprung zu diesem Ort führt. Dieser Pfeil repräsentiert genau einen Vektor, nämlich den Ortsvektor, der durch diesen Ort definiert wird. Im Video schauen wir uns die ganze Sache noch graphisch-optisch an.
Dieses Video eigent sich besonder für Menschen, die Wert auf eine mathematisch exakte, gleichermaßen aber auch anschauliche Definition des Ortsvektors legen. Deshalb wird genau darauf eingegangen, wie man verstehen kann, dass obwohl der Ortsvektor durch einen Ort definiert wird und es nur einen einzigen Pfeil gibt, der vom Koordinatenursprung zu diesem Ort führt, dieser Vektor eben doch nicht ortsgebunden ist.
Wer den Marathon der Suche im Netz nach einer exakten und widerspruchsfreien Definition des Ortsvektors hinter sich, wird am Ende des Videos sehr erleichtert sein.
Kugeloberfläche – Kosmetik und Nanopartikel
Gegeben sei eine Kugel. Teilen wir das Volumen dieser Kugel auf mehrere kleinere Kugeln auf, stellen wir fest, dass die Summe der Oberflächen der kleineren Kugeln größer ist als die Oberfläche der großen Kugel. Je kleiner die Kugeln sind, desto größer ist die Summe der Oberflächen. Im Alltag kommen mitunter sehr kleine “Kugeln” vor. Z.B. werden C60-Fullerene in manche Kosmetika eingearbeitet. C60-Fullerene sind Moleküle, die so ähnlich aussehen wie kleine Fußbälle. Unter anderem weil diese Moleküle pro Volumeneinheit eine “sehr große” Oberfläche haben, sind sie chemisch sehr reaktionsfreudig. Das bedeutet auch, dass – falls sie unerwünschte Nebenwirkungen wie z.B. Toxizität haben – diese Nebenwirkungen sehr groß sein können. In diesem Video wollen wir der Oberflächenvergrößerung bei Kugelverkleinerung mal mathematisch nachgehen. Übrigens finden wir die angesprochene Problematik in viele Bereichen des Alltags wieder, z.B. bei Feinstaub, den wir einatmen.
Vollständige Induktion
Die vollständige Induktion ist eine Beweismethode, mit der man (meistens) zeigt, dass eine Behauptung für jede natürliche Zahle gilt. Sie besteht aus zwei Schritten: 1) Man zeigt, das eine Behauptung für eine erste Zahl gilt – meistens die 1. 2) Man zeigt, dass wenn die Behauptung für eine bestimmte Zahl gilt, sie dann auch für die nachfolgende Zahl gilt. Daraus schließt man dann, dass die Behauptung für jede natürliche Zahle gilt. Im Video siehst du, wie du diese Methode anschaulich verstehen kannst, denn – wenn man so will – wenden wir diese Methode z.B. immer dann an, wenn wir irgendwo hinlaufen. Danach kannst du dann noch ein paar Beispiele sehen. Dabei werden Behauptungen mit der Methode der vollständigen Induktion bewiesen.